Throughout this Digital Signal Processing course, we are/will be seeing a trend of simplifying mathematical operations. From the various transforms (Laplace, Z, Fourier) to using different forms of number representations, the general objective is to simplify and optimize calculations. The twiddle factor is a major key component in this pursuit of simplicity. In this article, we will understand the twiddle factors’ purpose, definition, and applications.
Contents
What are twiddle factors?
Twiddle factors (represented with the letter W) are a set of values that is used to speed up DFT and IDFT calculations.
For a discrete sequence x(n), we can calculate its Discrete Fourier Transform and Inverse Discrete Fourier Transform using the following equations.
DFT: x(k) = 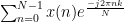
IDFT: x(n) = 
The computation procedure for the above is quite complex.
Twiddle factors are mathematically represented as:
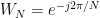
Rewriting the equations for calculating DFT and IDFT using twiddle factors we get:
DFT: 
IDFT: 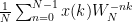
Why do we use twiddle factors?
We use the twiddle factor to reduce the computational complexity of calculating DFT and IDFT.
The twiddle factor is a rotating vector quantity. All that means is that for a given N-point DFT or IDFT calculation, it is observed that the values of the twiddle factor repeat at every N cycles. The expectation of a familiar set of values at every (N-1)th step makes the calculations slightly easier. (N-1 because the first sequence is a 0)
Alternatively, we can also say that the twiddle factor has periodicity/a cyclic property. We’ll graphically see this below.
Cyclic property of twiddle factors
For a 4-point DFT
Let’s derive the twiddle factor values for a 4-point DFT using the formula above.
For n=0 and k=0,


(From Euler’s formula: 
Similarly calculating for the remaining values we get the series below:
 = 1
= 1
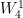 = -j
= -j
 = -1
= -1
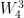 = j
= j
 = 1
= 1
As you can see, the value starts repeating at the 4th instant. This periodic property can is shown in the diagram below.

For an 8-point DFT
Let’s derive the twiddle factor values for an 8-point DFT using the formula above.
For n=0 and k=0,
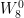 = 1
= 1
Similarly calculating for the remaining values we get the series below:
= 1
 = 0.707-0.707j
= 0.707-0.707j
 = -j
= -j
 = -0.707-0.707j
= -0.707-0.707j
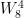 = -1
= -1
 = -0.707+0.707j
= -0.707+0.707j
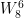 = j
= j
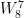 = 0.707+0.707j
= 0.707+0.707j
 = 1
= 1
As you can see, the value starts repeating at the 8th instant. This periodic property can is shown in the diagram below.

Matrix method of calculating DFT and IDFT with twiddle factors
The above DFT equation using the twiddle factor can also be written in matrix form. The matrix form of calculating a DFT and an IDFT eases up many calculations.
X(k) = 
![\left[ \begin{matrix} X(0) \\ X(1) \\ . \\ . \\ . \\ X(N-1) \end{matrix} \right] = \left[ \begin{matrix} { W }_{ N }^{ 0 } & { W }_{ N }^{ 0 } & . & . & . & { W }_{ N }^{ 0 } \\ { W }_{ N }^{ 0 } & { W }_{ N }^{ 1 } & . & . & . & . \\ . & . & . & . & . & . \\ . & . & . & . & . & . \\ . & . & . & . & . & . \\ . & . & . & . & . & { W }_{ N }^{ { (N-1) }^{ 2 } } \end{matrix} \right] \left[ \begin{matrix} x(0) \\ x(1) \\ . \\ . \\ . \\ x(N-1) \end{matrix} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Bmatrix%7D+X%280%29+%5C%5C+X%281%29+%5C%5C+.+%5C%5C+.+%5C%5C+.+%5C%5C+X%28N-1%29+%5Cend%7Bmatrix%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Bmatrix%7D+%7B+W+%7D_%7B+N+%7D%5E%7B+0+%7D+%26+%7B+W+%7D_%7B+N+%7D%5E%7B+0+%7D+%26+.+%26+.+%26+.+%26+%7B+W+%7D_%7B+N+%7D%5E%7B+0+%7D+%5C%5C+%7B+W+%7D_%7B+N+%7D%5E%7B+0+%7D+%26+%7B+W+%7D_%7B+N+%7D%5E%7B+1+%7D+%26+.+%26+.+%26+.+%26+.+%5C%5C+.+%26+.+%26+.+%26+.+%26+.+%26+.+%5C%5C+.+%26+.+%26+.+%26+.+%26+.+%26+.+%5C%5C+.+%26+.+%26+.+%26+.+%26+.+%26+.+%5C%5C+.+%26+.+%26+.+%26+.+%26+.+%26+%7B+W+%7D_%7B+N+%7D%5E%7B+%7B+%28N-1%29+%7D%5E%7B+2+%7D+%7D+%5Cend%7Bmatrix%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Bmatrix%7D+x%280%29+%5C%5C+x%281%29+%5C%5C+.+%5C%5C+.+%5C%5C+.+%5C%5C+x%28N-1%29+%5Cend%7Bmatrix%7D+%5Cright%5D+&bg=ffffff&fg=000&s=0&c=20201002)
Similarly an IDFT can be calculated using a matrix form using the following equation.
x(n) = 
Here, 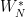
DFT as linear transform
The matrix of
We have the formula for calculating DFT using a matrix as:
X(k) =
x(n) = 
We also have the formula for calculating the IDFT using a matrix as:
x(n) =
Equating the last two equations:
= 

Here, ‘I’ is an identity matrix of order N. This equation represents the fact that the DFT displays linear transformation characteristics.
Now that we understand the twiddle factor, we can also see how it is used practically in the calculation of IDFT using the Decimation in Frequency FFT algorithm.